Publications
Robust and Safe Reinforcement Learning

Breaking the Curse of Multiagency in Robust Multi-Agent Reinforcement Learning
Laixi Shi*, Jingchu Gai*, Eric Mazumdar, Yuejie Chi, Adam Wierman.
In submission
[Arxiv]

Hybrid Transfer Reinforcement Learning: Provable Sample Efficiency From Shifted-dynamics Data
Chengrui Qu, Laixi Shi, Kishan Panaganti, Pengcheng You, and Adam Wierman
International Conference on Artificial Intelligence and Statistics (AISTATS Oral), 2025.
[Arxiv]
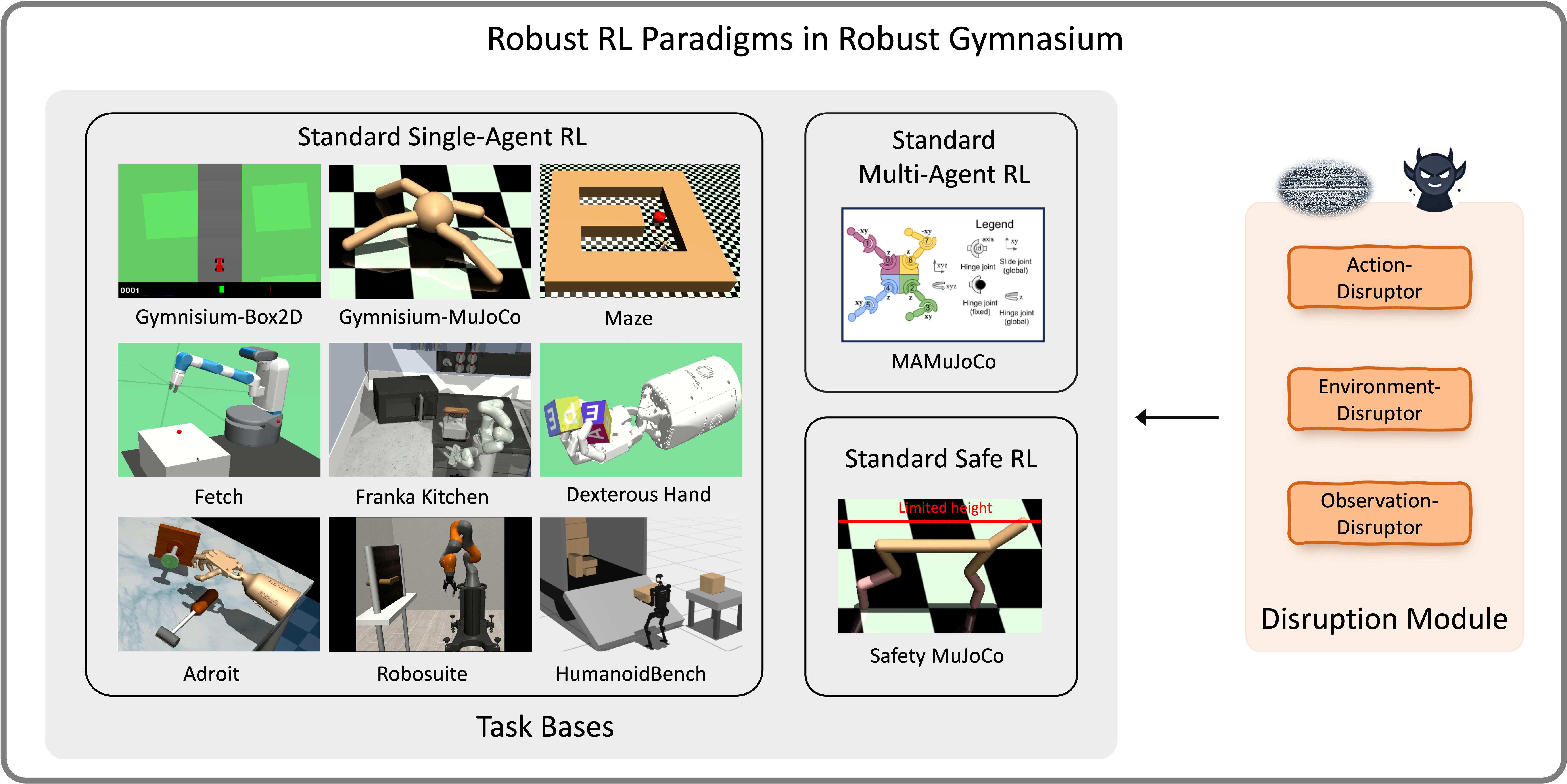
Robust Gymnasium: A Unified Modular Benchmark for Robust Reinforcement Learning
Shangding Gu*, Laixi Shi*, Muning Wen, Ming Jin, Eric Mazumdar, Yuejie Chi, Adam Wierman, Costas Spanos
International Conference on Learning Representations (ICLR), 2025.
[Github]
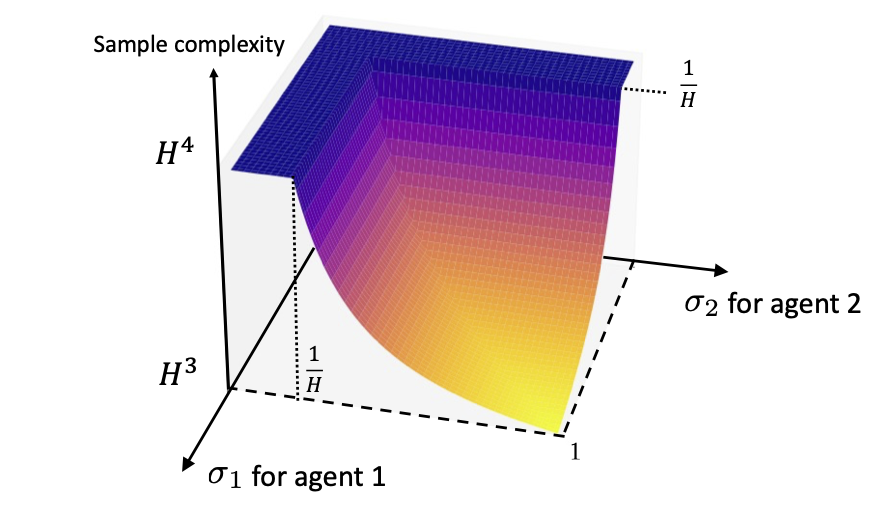
Sample-Efficient Robust Multi-Agent Reinforcement Learning in the Face of Environmental Uncertainty
Laixi Shi, Eric Mazumdar, Yuejie Chi, Adam Wierman.
International Conference on Machine Learning (ICML), 2024.
[Arxiv]
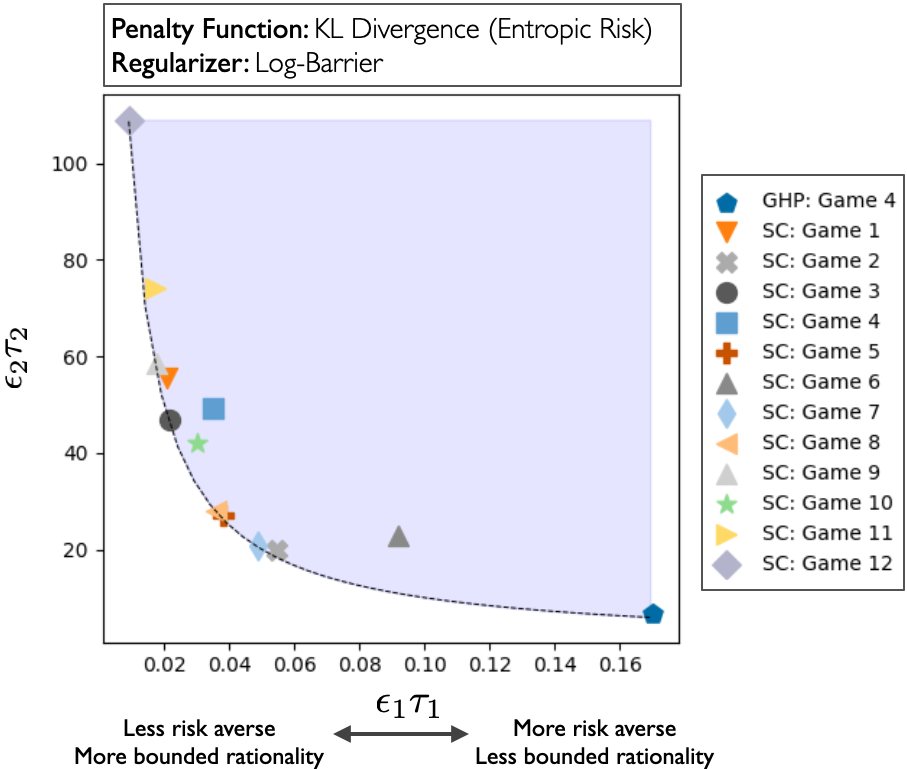
Tractable Equilibrium Computation in Markov Games through Risk Aversion
Eric Mazumdar*, Kishan Panaganti*, Laixi Shi*.
International Conference on Learning Representations (ICLR Oral), 2025.
[Arxiv]
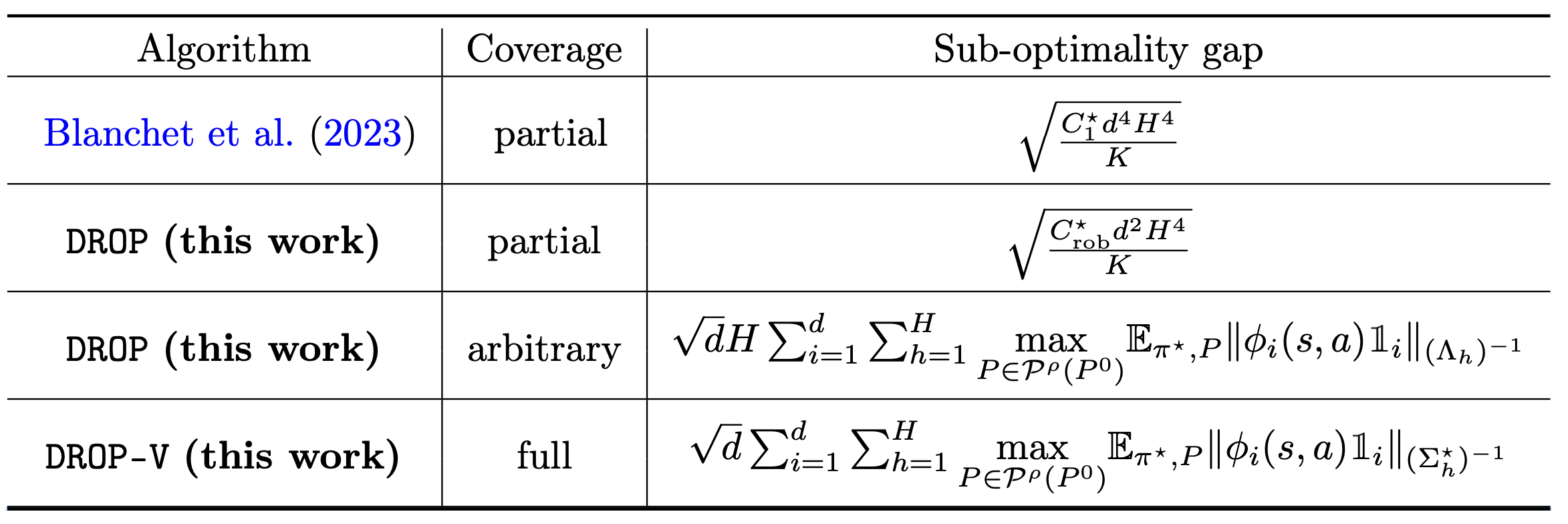
Sample complexity of offline distributionally robust linear markov decision processes
He Wang, Laixi Shi, Yuejie Chi.
Reinforcement Learning Conference (RLC), 2024.
[Arxiv]
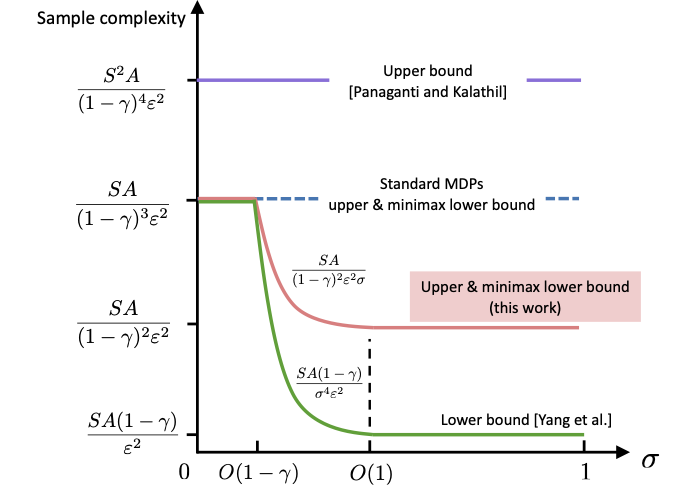
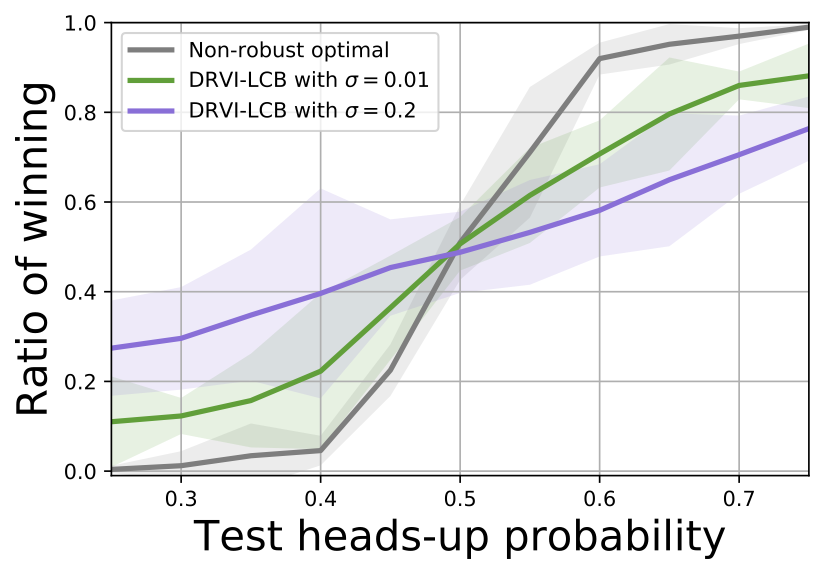
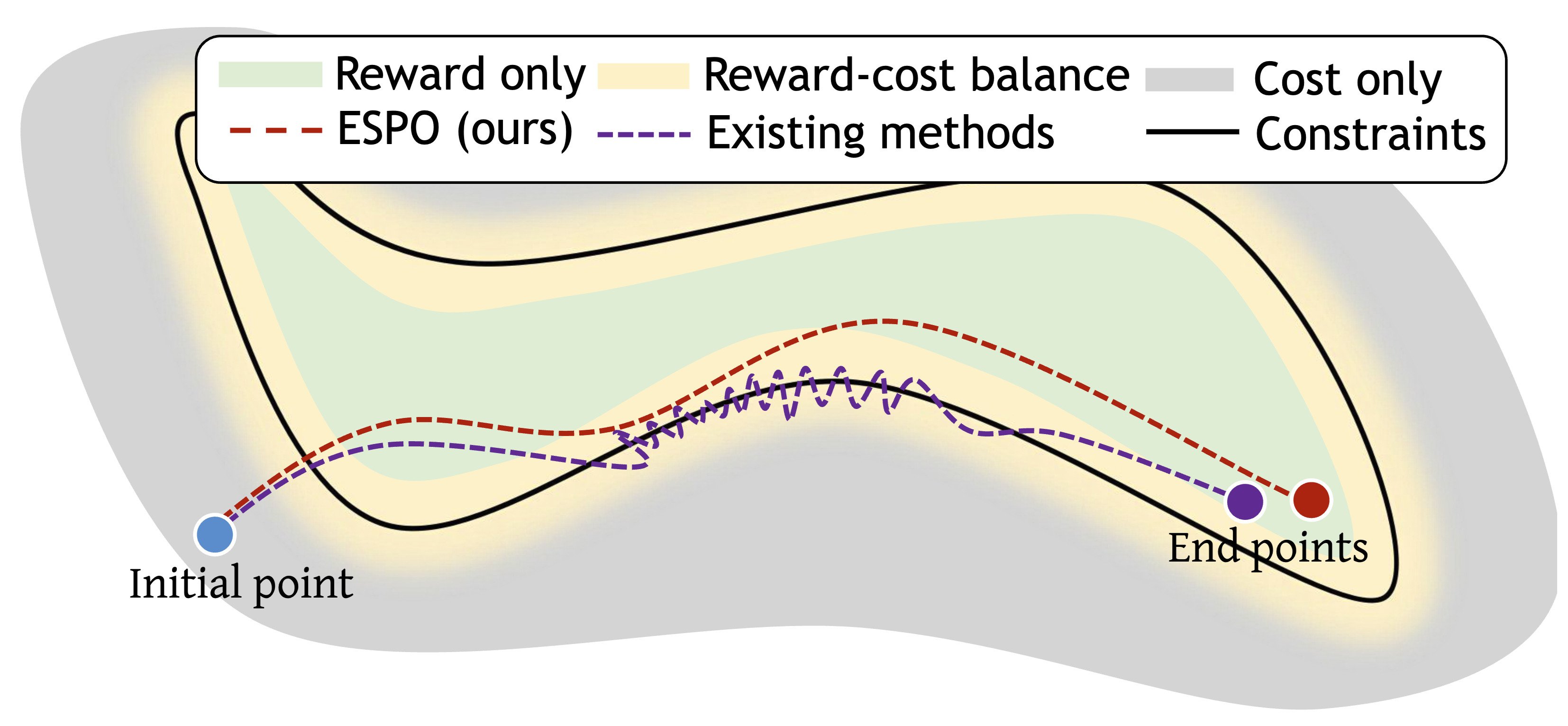
Enhancing Efficiency of Safe Reinforcement Learning via Sample Manipulation
Shangding Gu*, Laixi Shi*, Yuhao Ding, Alois Knoll, Costas Spanos, Adam Wierman, Ming Jin.
Conference on Neural Information Processing Systems (NeurIPS), 2024.
[Arxiv]
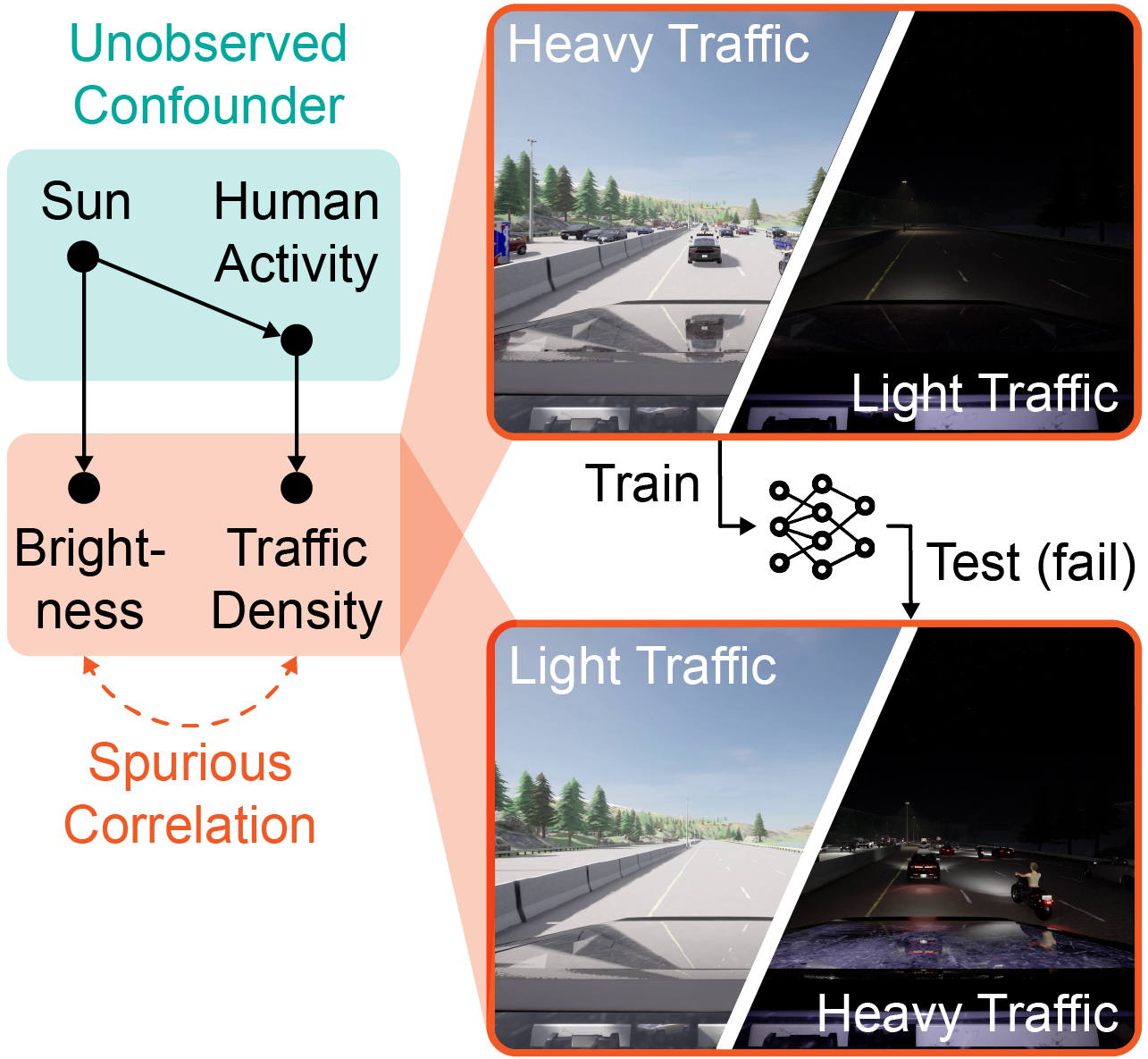
Seeing is not Believing: Robust Reinforcement Learning against Spurious Correlation
Wenhao Ding*, Laixi Shi*, Yuejie Chi, Ding Zhao.
Conference on Neural Information Processing Systems (NeurIPS), 2023.
The Second Workshop on Spurious Correlations, Invariance and Stability of ICML, 2023.
Data-Efficient Reinforcement Learning
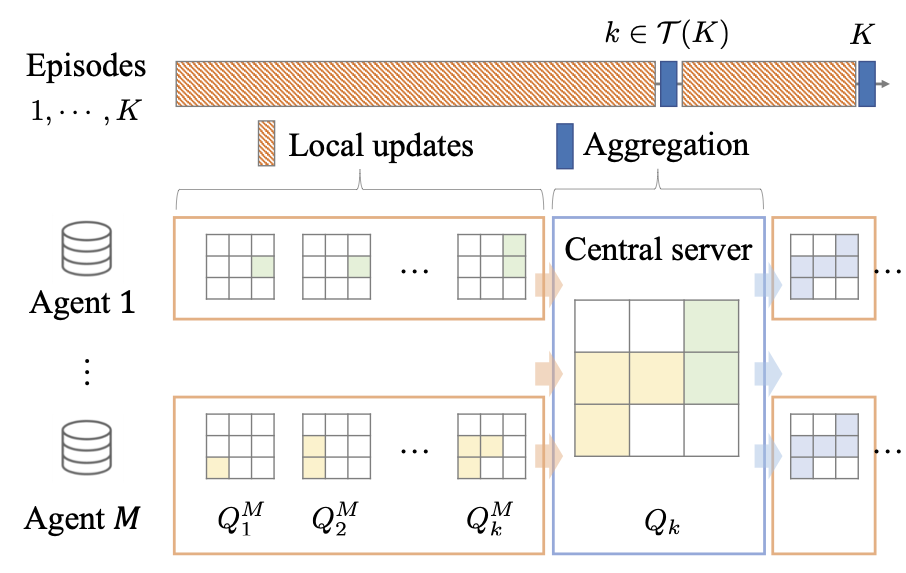
Federated Offline Reinforcement Learning: Collaborative Single-Policy Coverage Suffices
Jiin Woo, Laixi Shi, Gauri Joshi, Yuejie Chi.
International Conference on Machine Learning (ICML), 2024.
[Arxiv]
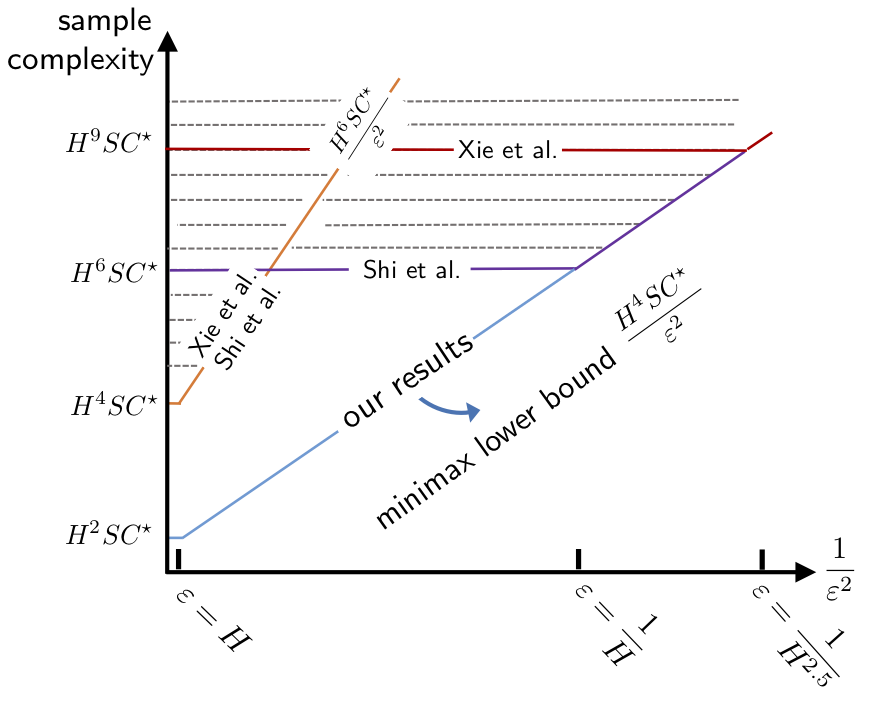
Settling the Sample Complexity of Model-Based Offline Reinforcement Learning
Gen Li, Laixi Shi, Yuxin Chen, Yuejie Chi, Yuting Wei.
The Annals of Statistics, 2024.
[Paper]
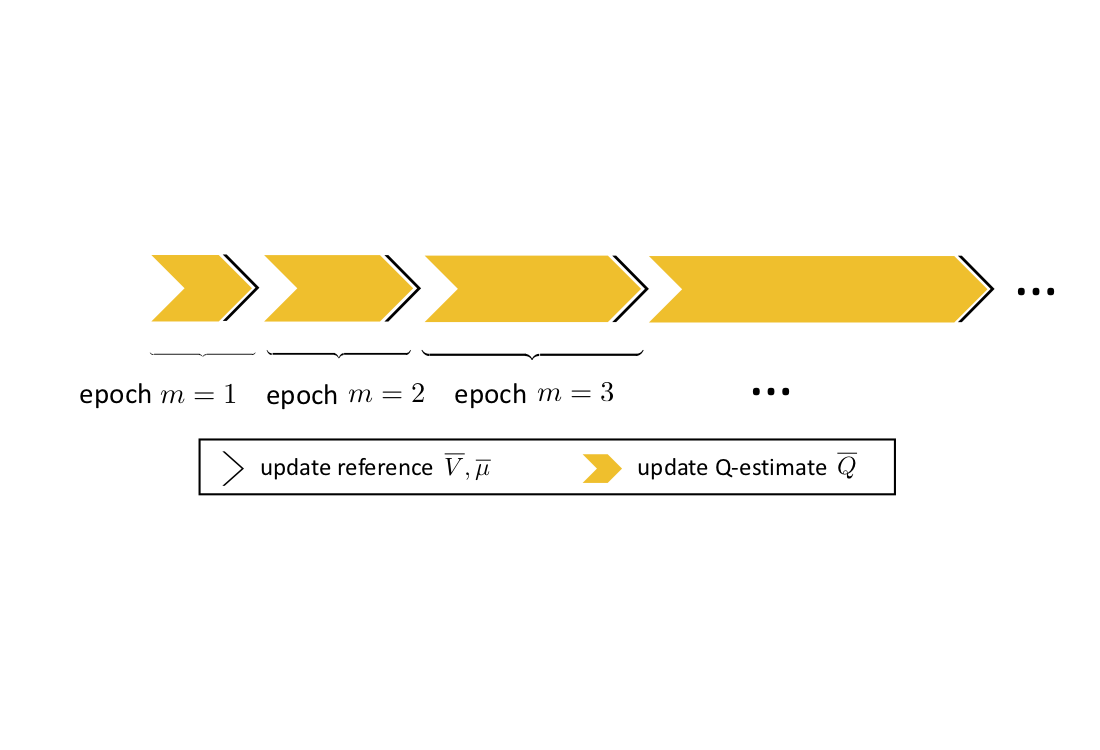
Pessimistic Q-Learning for Offline Reinforcement Learning: Towards Optimal Sample Complexity
Laixi Shi, Gen Li, Yuting Wei, Yuxin Chen, Yuejie Chi.
International Conference on Machine Learning (ICML), 2022.
[Paper]
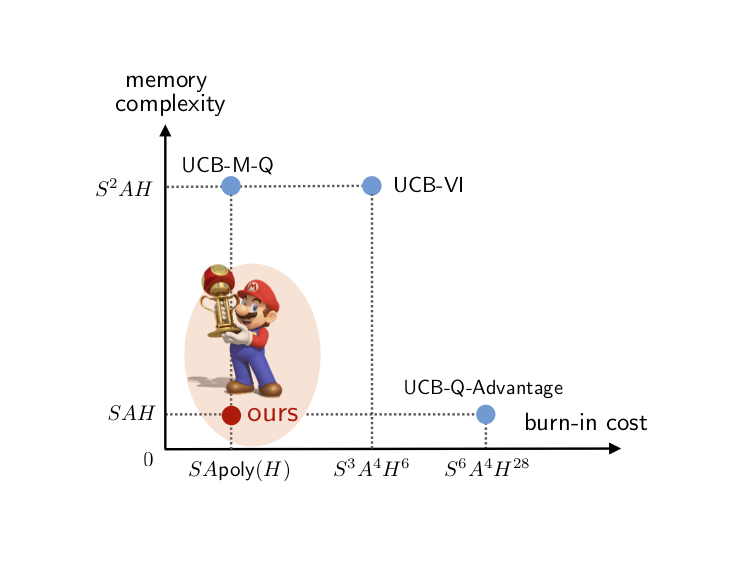
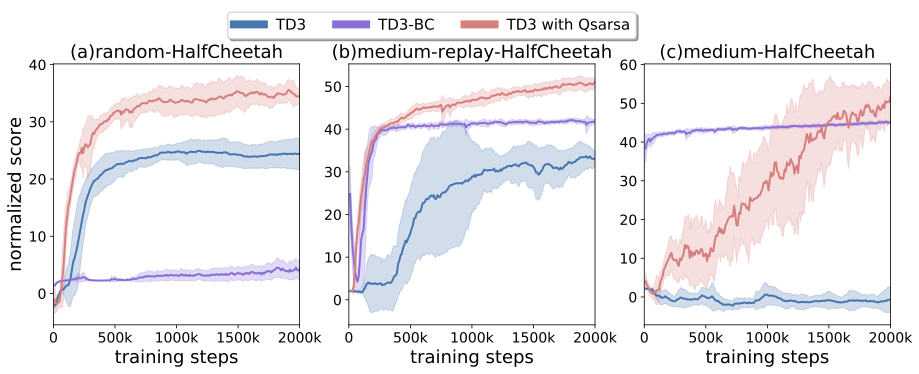
Offline Reinforcement Learning with On-Policy Q-Function Regularization
Laixi Shi, Robert Dadashi, Yuejie Chi, Pablo Samuel Castro, Matthieu Geist.
European Conference on Machine Learning (ECML), 2023.
[Arxiv]
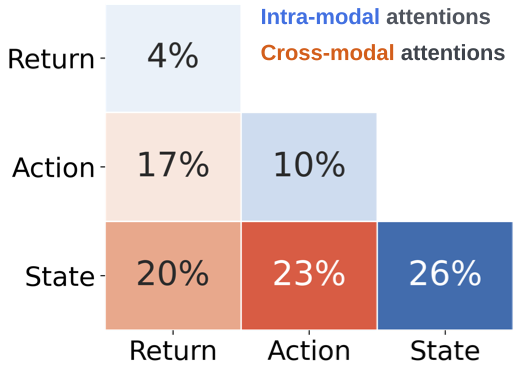
A Trajectory is Worth Three Sentences: Multimodal Transformer for Offline Reinforcement Learning
Yiqi Wang, Mengdi Xu, Laixi Shi, Yuejie Chi.
The Conference on Uncertainty in Artificial Intelligence (UAI), 2023.
[Paper]
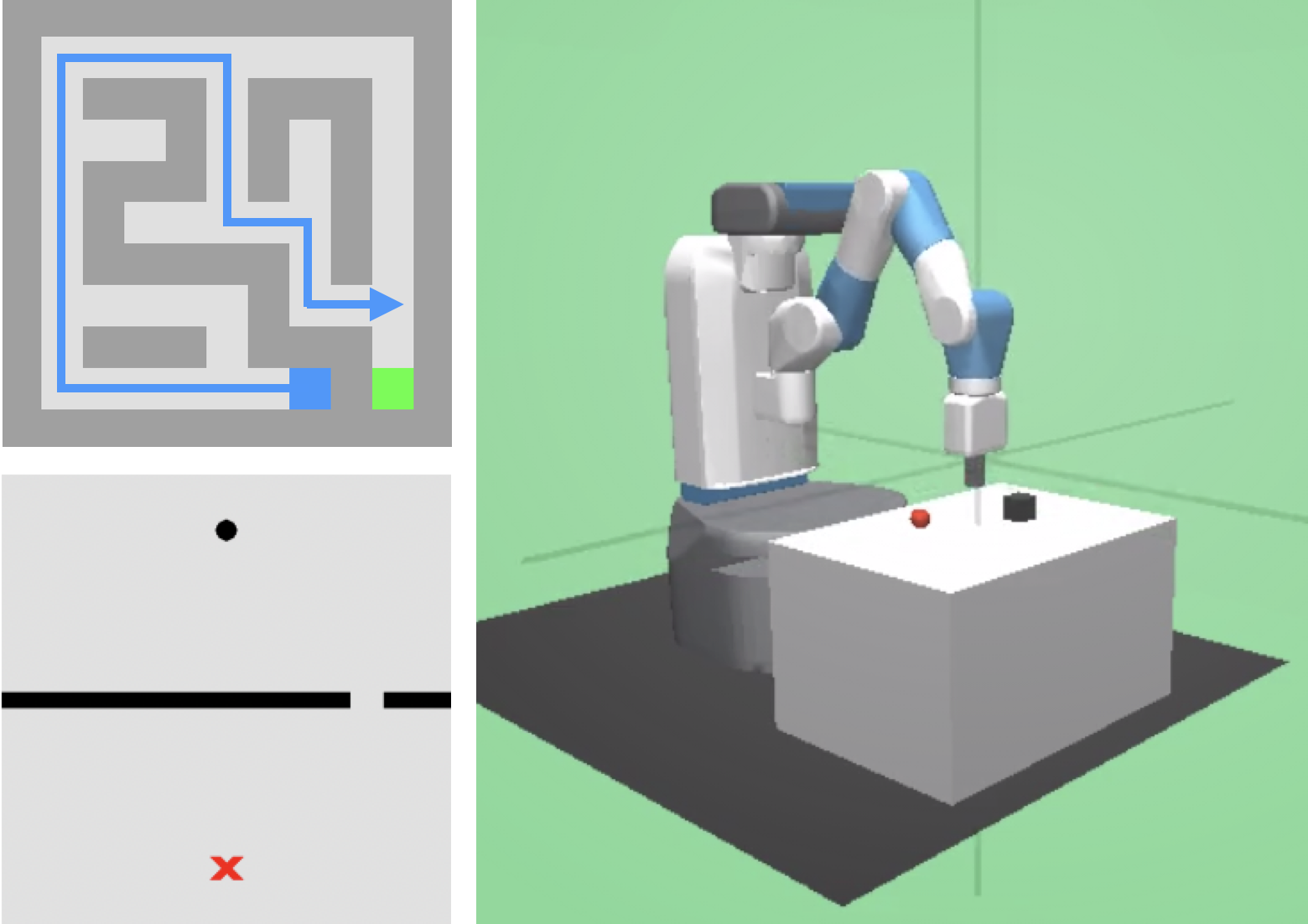
Curriculum Reinforcement Learning using Optimal Transport via Gradual Domain Adaptation
Peide Huang, Mengdi Xu, Jiacheng Zhu, Laixi Shi, Fei Fang, Ding Zhao
Conference on Neural Information Processing Systems (NeurIPS), 2022.
[Paper]
Data-Driven Optimization for Inverse Problems